【51CTO.com快译】如果您是公司里的运营人员,或是安全人员,那么您一定对事件管理这个概念并不陌生。所谓事件(或称突发事故)是一个广义术语。它描述了任何导致既定服务的质量产生骤降、或完全中断的有害事件。
而根据维基百科的解释,事件管理是指开发人员和IT运营团队为了响应系统发生的故障(事件),以尽快恢复服务的正常运营,而开展和经历的过程。显然,事件管理通常需要开发团队或运营团队的及时响应。而我们通常将此类处理团队称为值守(on-call)团队、或响应团队。
事件管理的5大流程
1.监控
作为事件管理过程的第一部分,监控可以协助管理人员发现系统中的问题,并从最终用户处验证该问题。一旦问题被确认,一个相应的事件就会被创建。系统也会根据该事件的性质,通知相关的团队成员。
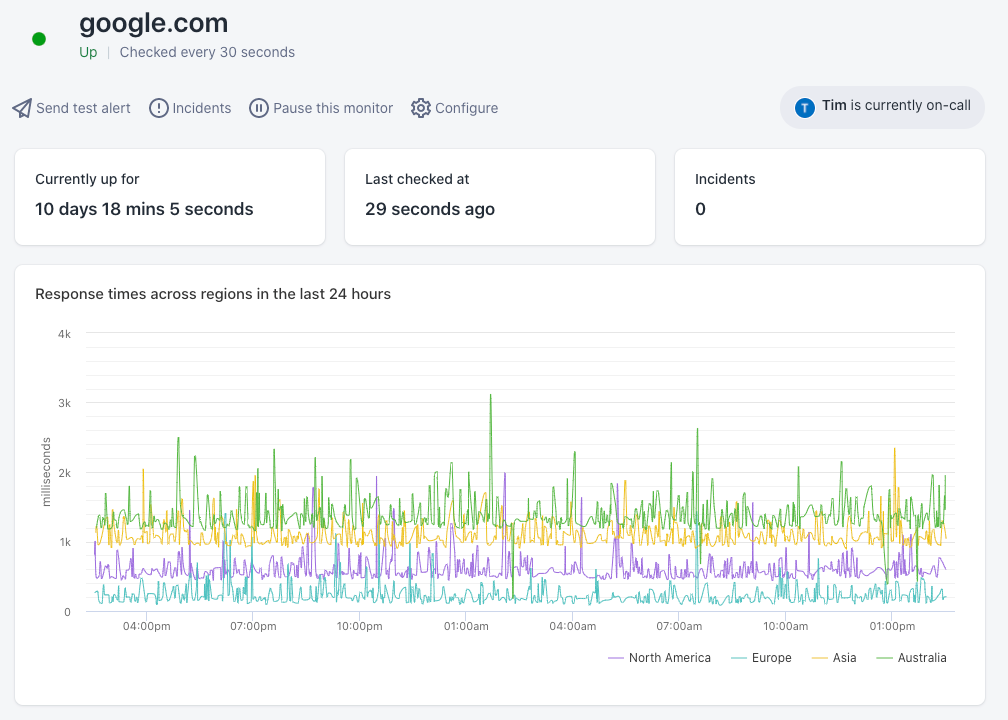
其中,一个最常见的示例便是:监控公司主页的可访问性,利用某个预先设置的特定监控器,每隔30秒自动检查一次目标网站。它一旦发现网站的访问速度奇慢、甚至不可达,便立即触发警报。这里的警报实际上是一种通知,其中包含了有关事件的基本信息。例如:“网站服务器不堪重负”之类的警报,就包含了流量何时激增等信息。下图是监控google.com可用性的界面截图。
2.值守计划
作为一种实践方式,值守是指既定的团队成员能够在既定的时间内响应各种警报。显然,企业应针对自身的事件管理需求,事先制定值守计划。毕竟,它可以确保处于“值守状态”的人员,从监控器处接收到事件警报,并且立即做出响应。
例如,企业可以事先安排好人员,在每个周末全天候(0:00至23:59)地进行值守。这就意味着无论是下午2点还是凌晨3点,只要有事件发生,他们就应马上做出响应。
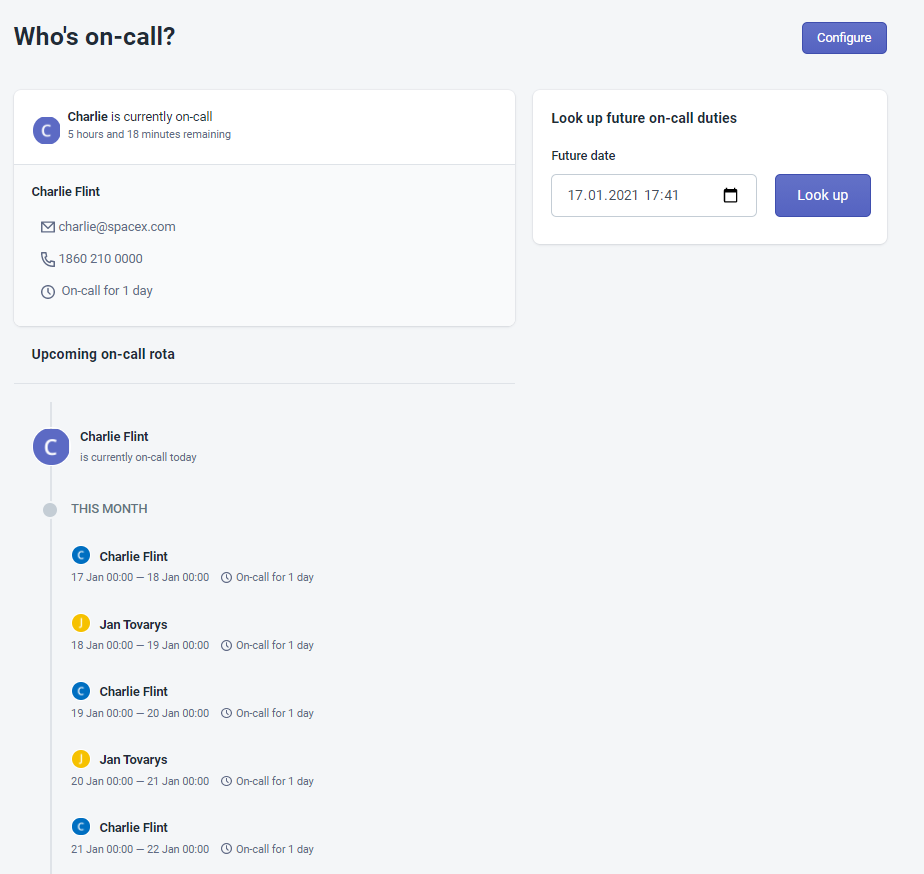
不同的组织对于处于“值守状态”的人员要求,可能不尽相同。有的要求具有极强的技术能力,可以独当一面;有的只要求能够及时通知并转发给相应的技术专家即可。当然,各个组织的目标都是相似的:它们需要在发生事件时,有人能够及时响应,随时介入和处理各种紧急情况。下图是一个值守计划的“电话树”示例。
3.警报
在发现了事件后,监控器该如何传递给处于值守状态的响应团队呢?在此,事件警报流程便可确保在正确的时间、系统以正确的方式、向正确的人员发出警报。为了达到将通知自动发送给特定团队成员的目的,我们可以采用短信、电话、通知推送等形式,及时发出警报。
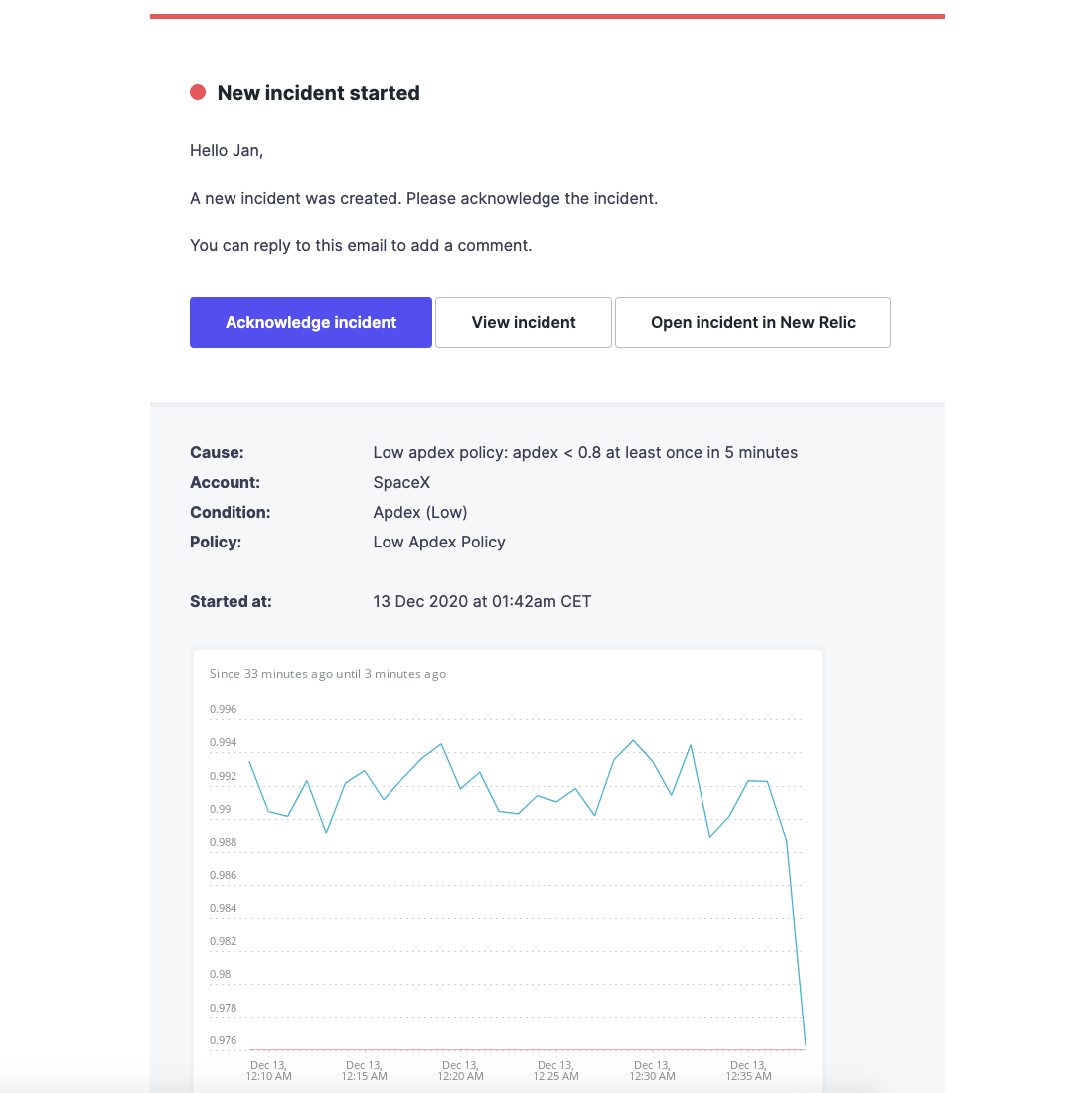
从内容上说,警报不应简单停留在普通的通知层面上,而需要能够提供有关事件的详细信息,以便协助响应团队找到原因,并快速解决问题。下图是spacex.com网站的电子邮件事件警报的示例。
4.沟通
虽然警报系统会自动通知响应团队,但是公司内部的其他团队,以及产品用户、或潜在客户又该如何知晓事件的发生呢?显然,事件一旦发生,响应团队与受其影响的各类人员应流畅地进行适当的沟通。为此,组织可以创建一个专有页面,以方便内、外部用户及时获悉状况,并能互通有无。
目前,Twitter和其他社交媒体应用都能够提供实用的小组件,方便组织广泛地发布与某个事件相关的渠道沟通页面。下图展示了某企业构建的、用以显示当前系统或服务状态的页面。
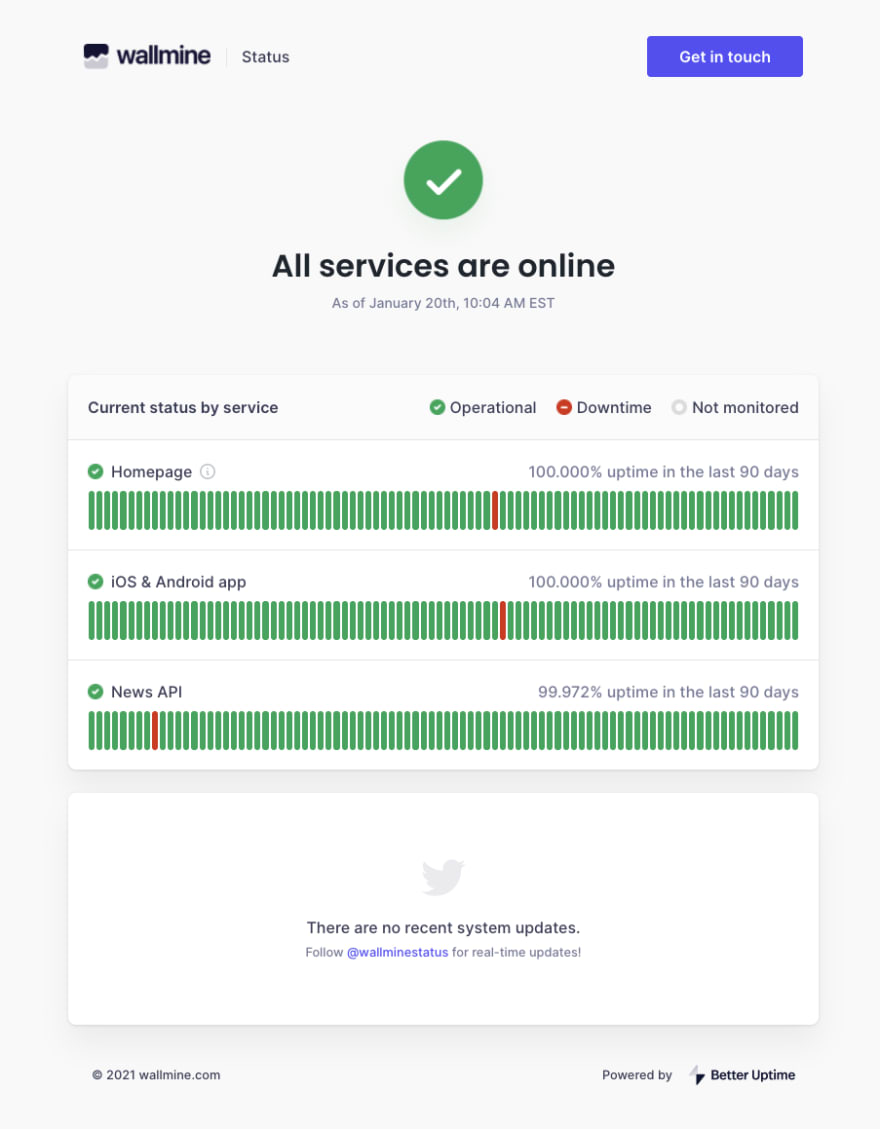
5.响应
事件响应的过程就是团队如何协作并解决事件的过程。由于不同的公司所使用的工具、软件、以及流程存在着差异性,因此不同的团队在该步骤的处理方式也不尽相同。
通常,为了找出导致事件发生的根本原因,许多团队会依赖特定的软件,以深入进行分析和排障。同时,为了方便统一的管理,此类事件的响应工具往往是集中式的。也就是说,通过各个团队成员之间的相互交流,所有信息都会被汇总到这里,这里记录并显示了事件发展的详细时间表,以及应对和解决该事件所采取的所有措施。当然,各种处理命令也会从这个单一的来源发布出去。下图展示了一个用于记录事件详细时间表的集中式响应平台。
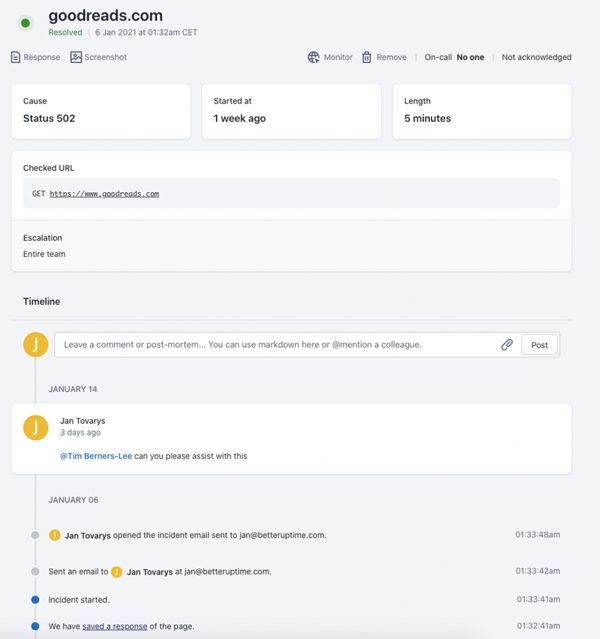
事件防御管理的各项优秀实践
1.事件监控的优秀实践
在实践中,我们往往希望发出的警报,能够像触发它们的监控工具一样及时准确。因此,在配置监控方案时,我们需要重点关注三个方面:事件验证、检查频率、以及警报阈值。
- 事件验证
为了确保事件发生的真实性。我们需要通过正确的事件验证机制,来保证响应团队不会收到毫无意义的误报。
- 检查频率
监控器检查目标服务的频率,决定了发现潜在事件的速度、以及发出警报的速度。例如:对于正常运行服务而言,30秒的检查频率,一般被视为一种良好的实践。
- 警报阈值
作为触发警报的条件,我们必须将那些能够触发事件的阈值设置得切合实际。可以说,正确的阈值设置既可以确保响应团队能够及时采取行动,又不会让他们频繁地出击,耗费人力与物力。
2.值守方式的优秀实践
如前文所述,业界并没有所谓“放之四海皆准”的值守计划安排。您可以根据本组织的实际情况与需求,创建合适的值守系统,其中需要重点考虑的是:团队的规模,各个团队所在的位置,单个团队成员的能力,以及他们的工作时间偏好。
- 呼叫循环(On-Call Rotation)
通过预先设置,我们可以将值守计划预设为呼叫闭环的方式,以避免出现人员响应上的单点空缺。具体说来,我们可以从如下方面进行设计:
团队规模
我们首先需要考虑的是现有的团队规模。例如,我们可以针对同一个岗位,设定两人一组的模式。即,角色A负责响应星期一、星期三、星期五和星期日;而角色B则负责星期二、星期四和星期六;下个周期他们的排班日对调。对于较大型的团队而言,这种循环方式比较普遍。
团队位置
当您的团队遍布世界各地时,为了给团队成员创造更好的工作生活平衡方式,您可以通过在不同的时区设置“追日(follow-the-sun)”式团队,既保证各个地区的成员仅在自己的白天时段值守,又保证了在任何时间点出现事件时都有人响应。
个人偏好
我们时常会发现自己的团队人员存在着多样性。有的人属于“早鸟”型,偏好在凌晨4:00到下午4:00值班;而有的人是“夜猫子”,更喜欢从下午4:00值班到凌晨4:00。这样,两人结对正好可以互相补足,并满足闭环值守的需求。
团队成员能力
在大多数情况下,并非所有团队成员都能够对同一系统具有相同的认知水平和技能。对此,我们可以根据他们的能力,设计出不同的职能与梯队。根据事件可能影响到系统的不同部分、以及事件本身的属性,我们可以分配给具有不同专长与能力的人员。下图是不同AB角值守小组的排班表。
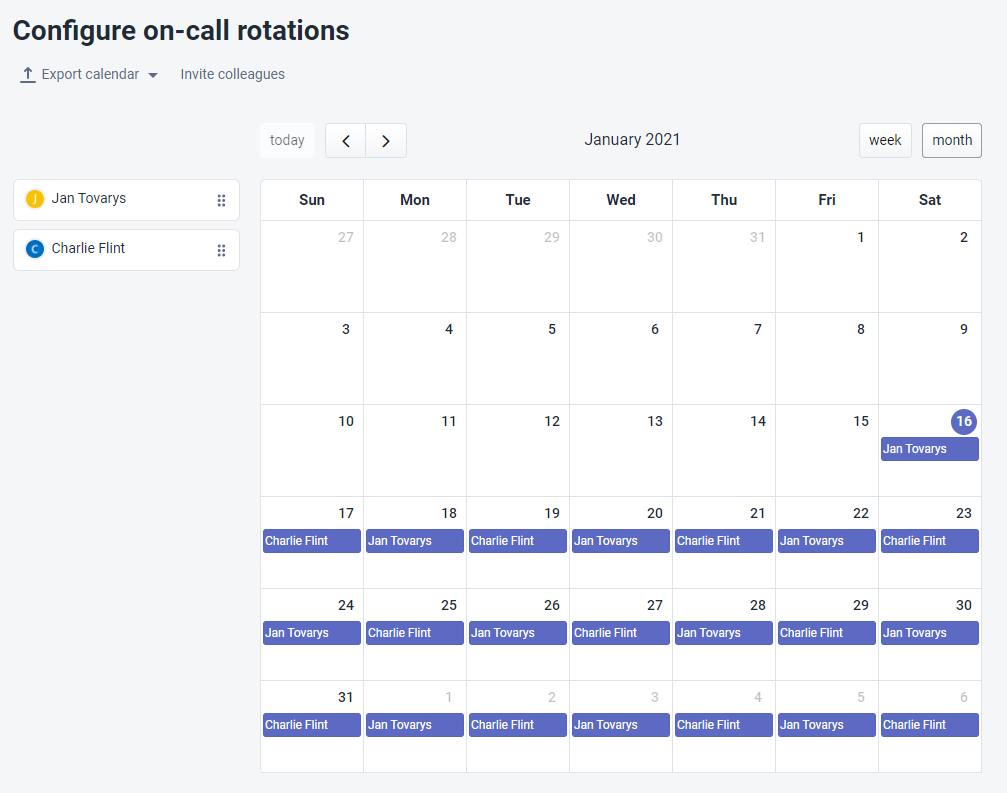
- 升级政策
常言道:“不要让皮球落地”。在碰到如下两种情况时,我们需要及时将事件予以升级。
- 第一响应者无法独立解决问题,需要其他团队成员的帮助。
- 无法确认第一个响应者已收到警报。例如:事件发生在深夜,触发的警报没能唤醒指定的第一个响应者,则系统会根据上述提到的“电话树”自动升级并呼叫第二个响应者。
基于资历的升级
理想情况下,我们可以根据“能者多劳”的原则,将事件处理的需求转发给最资深的人员。但是在现实情况下,这样可能让“能者”不堪其扰。因此,我们可以设置基于资历的升级方式,让升级链上的每个人都有机会得到事件处理的锻炼机会,同时也给资深人员提供了多级缓冲。
基于职能的升级
鉴于系统往往比较复杂,我们可以根据硬件设施、基础架构、交换网络、操作系统、软件应用、数据库等不同的职能角色,来设计升级的链路。
自动升级
有时候,事件的定义不够清晰,或者本身属性过于复杂。此时,我们需要设计默认的自动升级策略,或是直接到达团队领导处,或是根据严重程度升级到整个团队。下图是一个自动升级策略的示例。
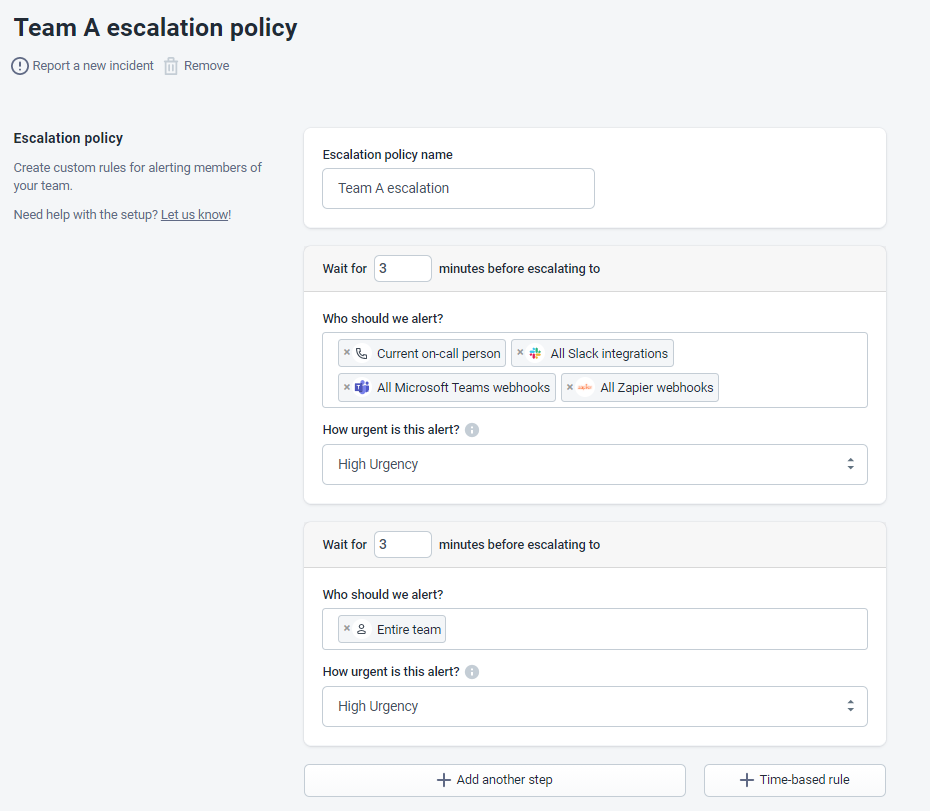
3.事件警报的优秀实践
与上述值守规则相比,事件警报的规则可以不唯一。总体而言,良好的警报实践就是让响应团队,能够通过正确的渠道,获得最少数量的所有必要信息。
- 正确地使用通知渠道
通常,我们可以通过电话、短信、Slack、Microsoft teams、以及电子邮件等推送方式,来获取服务中断等事件通知。就时效性而言,电话优于短信,短信优于电子邮件。因此,我们可以根据事件本身的优先级,选配不同的警报方式。
当然,在选择通知渠道时,我们也需要参考上面提到的值守方式和团队成员的偏好。例如,对于在办公室值守的人员而言,即时通信的方式会更高效,而电话则会产生更多的噪音;而对居家办公的人员来说,电话警报绝对是最佳的选择。
- 去重和分组警报
在发生某些严重的问题,或者波及面比较广时,系统通常会触发多个警报。对此,我们需要让警报系统自动对同类警报采取去重处理,以免产生“霸屏”的现象。同时,我们可以将相关的警报划归为一组,以方便响应团队进行深入分析和研究。
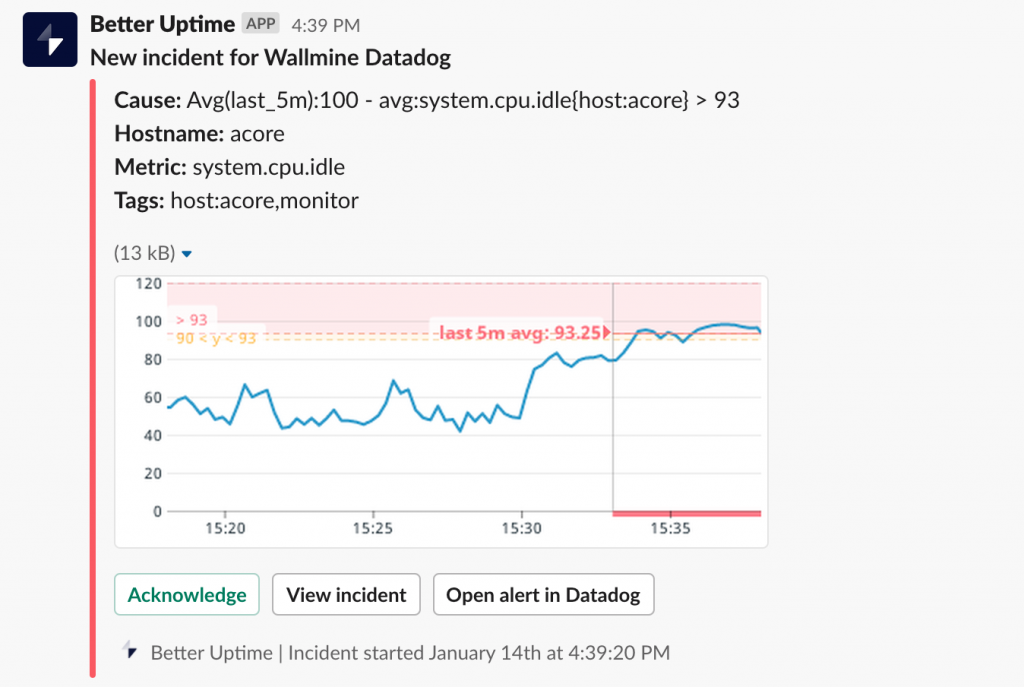
- 创建实用的警报
对于响应团队而言,他们往往希望收到不只是简单的警报,而是包含了诸如事件日志、错误截图、以及系统性能图等高质量的状态数据信息,进而能够大幅简化诊断和调试的过程。下图是由Slack发送的实用警报的示例。
- 避免警报疲劳(Alert Fatigue)
人类是有惰性的。面对长期收到的海量警报,值守团队会逐渐在心理上调高对于事件的容忍度。他们或是会误判为“假警报”,或是对某些严重的问题产生了“懒政”的情绪,甚至会故意忽略它们。对此,我们需要通过前面提到的去重等手段,来减少警报的总量。具体方法请参见:《平均响应时间(MTTR)和事件管理的KPI》一文。
4.事件沟通的优秀实践
大家都知道,在发生事件时,流畅、透明的沟通方式,不但能够及时止损,而且更方便了响应团队的联合“作战”,协同攻坚。我们可以通过如下三种方式,来实现事件的顺畅沟通。
- 创建实用的状态页
许多公司都会使用专用的状态页面,来作为重要事件的交流渠道。通常,该页面上可以显示有关事件的来龙去脉。通过访问或订阅该状态页,响应团队可以在页面上实时更新、发布、或接收最新的信息。
- 利用嵌入式状态
将事件传达给网站访问者或用户的最简单方法,莫过于使用嵌入式状态。它会作为嵌入式窗口部件显示在网站的顶部,并告知用户事件的详细信息。如果用户单击它,就会跳转到专门提供详尽信息的状态页面。据此,系统运营方可以及时与用户沟通服务中断的相关信息。
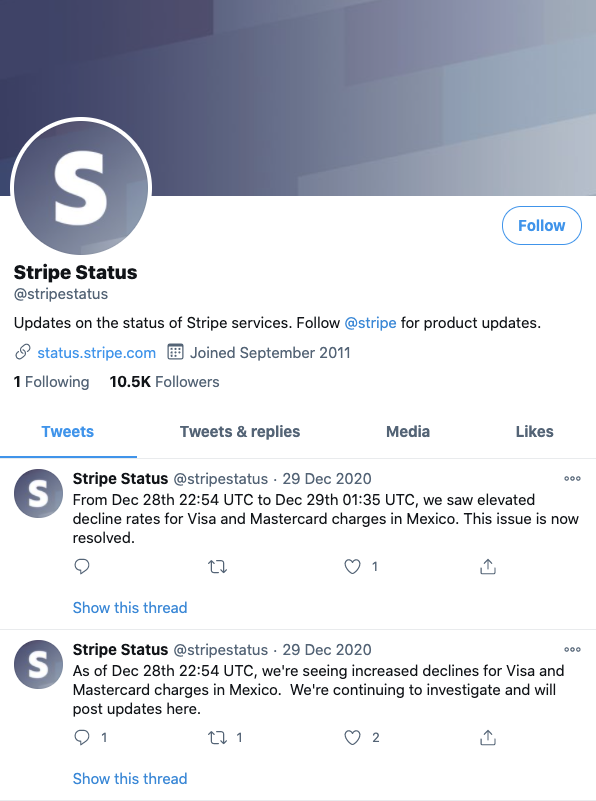
- 不要忽视社交媒体
如今,由于人们时不时地会查阅社交媒体上的订阅信息,因此许多公司都已选用社交媒体账号来发布它们的重要通知。例如,有些公司会选用Twitter来广播服务停机的时间,及时更新它们的账号主页状态,甚至与订阅用户开展简单的问答互动。下图是Stripe公司在Twitter上的状态页面。
5.事件响应的优秀实践
在实际解决事件的过程中,我们不能指望技术专家能够迅速一针见血地修复所有故障。为此,我们可以利用集中式的任务控制工具,提前制定好标准化的诊断过程和行动步骤,以便团队里的每个成员都可以遵循并接收行动指导。
- 制定行动计划
在行动计划的制定过程中,我们可以针对响应团队的不同职能角色,通过预定义场景的形式,给出if-then之类的详细步骤,协助他们诊断出根本原因。为了避免人为判断上的偏差,行动计划应提供默认选项,以及按需在重点步骤处,附加相关文档或参考手册。
- 集中任务控制
由于时间紧、任务急,响应人员往往希望能够“一站式”地开展工作。因此,我们需要提供一个集中式的工作平台,访问团队按需获取诸如:联系人列表,值守人员信息、以及升级策略等必要信息,以避免他们在各种工具与文档之间来回切换,“大海捞针”。
同时,集中式任务控制能够以统一的时间戳,精准地记录下事件处理的全过程。其中包括:谁在什么时刻,采取了哪些步骤,解决了哪个问题点。这样既避免了重复记录,又实现了有案可查,对于事后评估处理的KPI非常实用。
- 不要低估事后
事后整改往往是事件处理整体环节中容易被忽略的一项。针对事件,相关职能部门应及时开展自查工作,防止类似事件的复发。而响应团队也需要通过处理记录和KPI,来评估执行的效果,分析与原定计划的偏离原因,总结经验教训,进而提出改进的方案。
原文标题:Incident Management in 2021: From Basics to Best Practices,作者: Jan Tovarys
【51CTO译稿,合作站点转载请注明原文译者和出处为51CTO.com】