引言
人工智能、大数据与云计算三者有着密不可分的联系。人工智能从1956年开始发展,在大数据技术出现之前已经发展了数十年,几起几落,但当遇到了大数据与分布式技术的发展,解决了计算力和训练数据量的问题,开始产生巨大的生产价值;同时,大数据技术通过将传统机器学习算法分布式实现,向人工智能领域延伸;此外,随着数据不断汇聚在一个平台,企业大数据基础平台服务各个部门以及分支机构的需求越来越迫切。通过容器技术,在容器云平台上构建大数据与人工智能基础公共能力,结合多租户技术赋能业务部门的方式将人工智能、大数据与云计算进行融合。
数据处理的发展阶段
随着信息技术的蓬勃发展,特别是近十年,移动互联技术的普及,运营商、泛金融、政府、大型央企、大型国企、能源等领域数据量更是呈现几何级数的增长趋势。数据量的膨胀除了带来了数据处理性能的压力外,数据种类的多样性也为数据处理手段提出了新的要求,大量新系统的建设同时产生了众多数据孤岛,给企业的数据运营维护与价值发掘带来了重大的挑战。随着大数据技术的不断发展,企业的数据处理技术转型也经历了几个阶段,如图1所示。
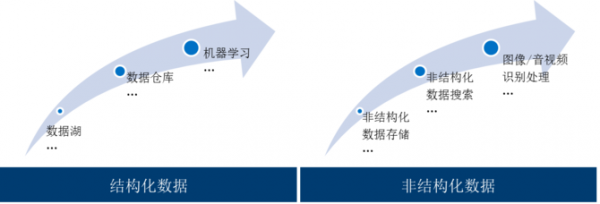
▲图1 企业数据处理转型的阶段变化
在***阶段,大数据技术发展的早期,为了打破数据孤岛,将各类数据向大数据平台汇集,形成数据湖的概念,作为多源、异构的数据的数据归集,在此基础上进行数据标准化,建立企业数据的汇聚中心。在这个阶段,对非结构化数据处理以存储检索为主,对结构化数据处理提供各类API和少量SQL支持,使海量的以SQL实现为主的业务难以迁移到大数据平台,新业务开发使用门槛高,大数据技术的推广受到阻碍。
在第二阶段,企业客户的需求集中表现为,如何更好地处理结构化数据以及将老的IT架构迁移到分布式架构中。各大数据平台厂商开始在SQL on Hadoop领域进行研发和竞争,不断提高SQL标准的兼容程度。在这个过程中,Spark诞生并逐渐取代了过于笨重且TB量级计算性能存在缺陷的MapReduce架构,Hadoop技术开始向结构化数据处理分析更深度的应用领域进发。随着SQL on Hadoop技术的不断发展与星环科技解决了Hadoop分布式事务的难题,越来越多的客户在Hadoop上构建新一代数据仓库,将Hadoop技术应用于越来越多的业务生产场景,技术门槛的降低,使越来越多的客户可以利用强大的分布式计算能力轻松分析处理海量数据。在这个阶段后期,随着企业客户对实时数据分析研判需求的不断提高,流处理技术得以蓬勃发展。
在第三阶段,一部分企业已经完成了由基于关系型数据库为核心的数据处理体系向基于大数据技术为核心的数据处理体系的转变。在本阶段早期,很多企业客户不满足于通过SQL基于统计对数据的分析和挖掘,促使传统的机器学习算法开始实现分布化,但主要还是针对结构化数据的学习挖掘。随着深度学习技术和分布式技术的碰撞,演化出了新一代的计算框架,如TensorFlow等,计算能力的提升,并结合大量训练数据,使机器学习人工智能技术在结构化与非结构化数据领域产生巨大威力,开始应用于人脸识别、车辆识别、智能客服、无人驾驶等领域;同时,对传统机器学习算法产生了巨大冲击,一定程度上减少了对特征工程与业务领域知识的依赖,降低了机器学习的进入门槛,使人工智能技术得以普及。另一方面,可视化的拖拽页面、丰富的行业模板、高效率的交互式体验,极大地降低了数据分析人员的使用门槛,让人工智能技术进一步走入企业的生产应用。
大数据、人工智能与云技术的融合
随着企业内部对于数据资源的应用不再仅仅局限于IT部门,越来越多的内部项目组与分支机构加入大数据平台的使用中,加之数据处理技术的不断发展,如何解决基础平台的资源隔离问题、管理分配问题、编排调度问题;如何将企业业务应用需要的基础服务能力做更好地抽象,降低应用所需的基础服务的环境搭建、开发、测试部署周期,提升IT支撑效能;如何更好地管理众多的基于大数据与人工智能开发的应用等等成为企业急需解决的问题。
在大数据技术发展的早期,仅仅是在计算框架MapReduce中提供简单的作业调度算法,随着资源管理的需求,在Hadoop 2.0时代,Yarn作为单独组件负责分布式计算框架的资源管理。但是,一方面,Yarn仅仅能够管理调度计算框架的资源;另一方面,资源的管理粒度较为粗放,不能做到有效的资源隔离,越来越不能满足企业客户的需求。
云计算技术作为资源隔离封装虚拟化,以及管理调度的技术,本应应用于解决上述问题。但是,在Docker容器技术被广泛接受之前,云计算虚拟化技术主要基于虚拟机封装资源,并在其之上加载操作系统,资源利用率低,早期有厂商尝试将大数据平台构建在基于虚拟机技术的云化方案上,由于资源利用和稳定性问题,在私有云上的尝试鲜有成功案例。在公有云方面,借助公有云较为强大的基础平台硬件与运维支持能力,有一些非核心业务的应用尝试。
随着Docker、Kubernetes等容器技术的发展,与微服务等技术概念的形成,大数据与人工智能基础平台开始基于容器云构建底层资源管理与调度平台。容器云就像一个分布式的操作系统,将集群中的各类硬件资源进行封装、管理以及调度,将封装的资源作为容器承载大数据的相关组件进程,再将这些容器进行编排,组成一个个的大数据和人工智能的基础服务,如分布式文件系统HDFS、NoSQL数据库Hbase、分布式分析型数据库Inceptor、分布式流处理平台Slipstream、分布式机器学习组件Sophon等。由这些基础服务编排构建公共能力服务层,提供如数据仓库、数据集市、图数据库、全文搜索数据库、流处理服务、NoSQL数据库、机器学习平台服务、定制图像识别服务等,为企业打造全新的数据处理核心系统。基于这一核心系统服务于各类企业的不同部门。通过资源隔离技术,通过对每个租户的资源分配和权限管理,满足业务分析人员的个性化分析需求,专注于业务逻辑的开发和数据的分析挖掘。
技术融合的应用
中国邮政大数据平台建设以Transwarp Data Hub(以下简称TDH)与Transwarp Operating System(以下简称TOS)作为基础架构系统,搭建的新一代逻辑数据仓库和数据集市,完全取代了Teradata和Oracle.
总体架构与实现
中国邮政大数据平台服务于量收、邮务、名址等系统,同时运用容器云TOS实现创新多租户的数据分析挖掘环境。建立从业务层到管理层到决策层的智能分析体系,模拟量化风险和收益,实现对邮政各种业务数据进行分类、管理、统计和分析等功能,给各级管理人员提供各类准确的统计分析预测数据,使其能够及时掌握全面的经营状况,为宏观决策提供支持;为省分公司基层业务人员提供详尽的数据,供其对各自的工作目标、当前和历史状况进行准确的把握,对业务活动进行有效支撑,满足邮政经营分析管理及决策支持。
中国邮政大数据平台以五大基础服务集群域为基础,分别是数据湖集群域、企业数据仓库集群域、省分服务集群域、机器学习实验室集群域、开发/测试/培训集群域。
(1)数据湖集群域:基于TDH平台搭建的数据湖,主要承担多源异构的数据归集,数据湖内包括:原始数据池、清洗加工数据池、整合加工数据池等。
(2)企业数仓集群域:基于TDH搭架的数据仓库集群,基于大数据创新搭架逻辑数据仓库,用于迁移改造原有基于Teradata搭架的数据仓库,数据集市和基于Oracle搭建的报刊集市的邮政量收管理系统。
(3)省分服务集群域:基于TOS搭建容器化多租户数据分析平台云。为省、市分公司开发人员和业务人员提供省分多租户的平台环境,集团分发数据与自有数据存储计算,自有应用的开发与管理,独立租户使用运行。
(4)机器学习实验室集群域:基于TOS搭建的容器化多租户大数据机器学习平台,为集团数据中心分析师提供多租户的开发实验环境平台,进行数据探查、业务建模、算法研究、应用开发、成果推广等。
(5)开发/测试/培训集群域:为应用开发人员、系统测试人员、培训师、学员提供多租户的大数据与机器学习平台,为开发商及内部单位提供开发测试培训服务。
以此为基础,达到了数据管理、服务管理、运维管控、安全管控四个维度的统一。在风险管控、决策支持、服务支撑、流程优化、品牌创新、交叉营销六大应用领域展开应用。实现了租户管理、数据治理、数据加工、数据挖掘、数据探索、数据展现六大平台功能。
数据湖和数据仓库基于TDH构建,将包括业务系统数据、实时流数据、合作单位数据、互联网数据等不同数据源,通过ESB接入、ETL工具、Kafka、Sqoop、文本上传、人工接入等方式,统一汇聚进入数据湖。加工后获得的数据资产发布到数据资产目录,通过数据资产目录的构建TDH与TOS用户间数据交互体系。便于用户快速检索数据,通过数据资产目录实现对数据的集成、融合、安全、共享。数据资产目录包括:元数据、主数据、数据安全、数据标准、数据质量、数据轮廓、数据生命周期等。此外,企业用户通过大数据门户按需申请租户存储计算资源、数据资源、审批流程通过后,集群资源管理员按需快速部署集群,自动化将数据从数据湖加载入数据分析集群或省分集群对应的租户空间,供数据开发人员使用。数据开发人员会将数据应用成果固化到数据湖内,对外提供数据服务。
数据仓库与数据集市的完整迁移
中国邮政大数据平台是全球***采用Hadoop(TDH)技术完全取代Teradata和Oracle的混合架构搭建新一代逻辑数据仓库和数据集市的系统。
原量收系统使用Teradata的数据仓库和Oracle的数据库,数据使用空间目前已接近30TB,现有使用用户约5万人,提供近约900张报表的灵活查询,单日报表查询频次***能达到40万次,月初高峰查询需支持约2000计算查询并发。
通过项目前期大量调研准备工作,制定了切实可行的项目实施方案。量收管理系统的总体架构、ESB、BI工具、ETL工具、调度工具、门户等都保持不变,仅将原量收系统的数据仓库和数据集市,使用大数据平台进行完全替换,降低了整个迁移风险。
整个迁移过程中,包括环境部署、模型迁移改造、接口迁移改造、数据迁移、ETL迁移改造、报表迁移改造、数据核对、性能优化、业务应用迁移、风险控制,系统测试等。例如模型迁移改造,不改变原有业务逻辑,只需对接口层模型,基础层模型、汇总层模型进行轻度改造。对于模型改造来说,系统基础层模型结构相对复杂,关联度相对较高,原系统使用Teradata数据库。TDH全面兼容Teradata的数据类型与SQL方言,降低了迁移成本。同时迁移完成后,性能大幅提升,见图2.
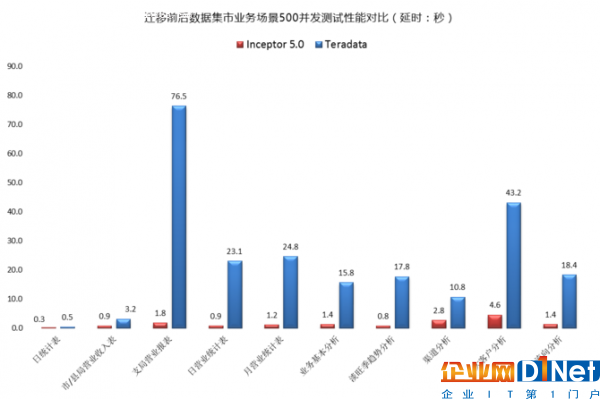
▲图2 迁移前后数据集市业务场景500并发测试性能对比
基于容器云的大数据与机器学习平台的全面应用
基于TOS实现的多租户新模式,将大数据与机器学习平台组件完全容器化实现,并在TOS提供能力服务。集团统一部署企业内部云平台,对邮政各个租户(集团、省分、市局等)动态分配存储、计算、网络等资源,并实现完整的资源隔离,使得各个租户数据分析人员和业务人员获得相对独立的资源环境,赋能业务创新,同时可动态调配资源,实现资源的共享优势。
集团、省分、市局各级人员通过多租户平台,实现资源发布、申请,使用及应用开发、成果推广。通过项目立项申请审批后,省分项目组人员在租户空间内,接入访问数据资源,使用平台服务资源,大数据分析工具及机器学习挖掘工具展开数据分析挖掘工作,具体开展数据处理、模型开发、算法应用、应用发布等,在审批验收之后,将成果推广到数据湖上部署对全集团提供数据应用服务。
通过TOS+TDH搭架厚平台、薄应用的微服务架构,实现租户之间的异构性、独立测试与部署、资源按需伸缩、高性能计算能力、租户间错误问题隔离、团队全功能化。实现数据资产化管理。面对集团数据多样、海量、跨板块、跨专业的需求,集团对数据进行了全面梳理,创新集成各版块、专业数据,创建数据资产目录便于快速检索获取资产,管控治理资产,让数据即资产从理论阶段上升到实现阶段。
结语
随着企业数据处理与服务需求的不断发展,由大数据的汇聚,分布式技术释放计算能力开始,技术不断延伸发展,大数据、人工智能与云计算的边界越来越模糊,三者技术的发展不断互相影响与融合,这是发展与需求产生的自然趋势。在“后大数据时代”,基础大数据与人工智能云平台的形成与落地会越来越多,真正实现科技赋能业务,为企业提升效率与发展提供更强的心脏。同时,未来可以看到,企业可能会将其基于基础能力平台的应用体系也上架到平台的应用市场中,充分利用云平台的优势能力,资源共享,统一管理。
【编辑推荐】