最近一个有意思的现象,是机器阅读理解突然开始热络了起来。
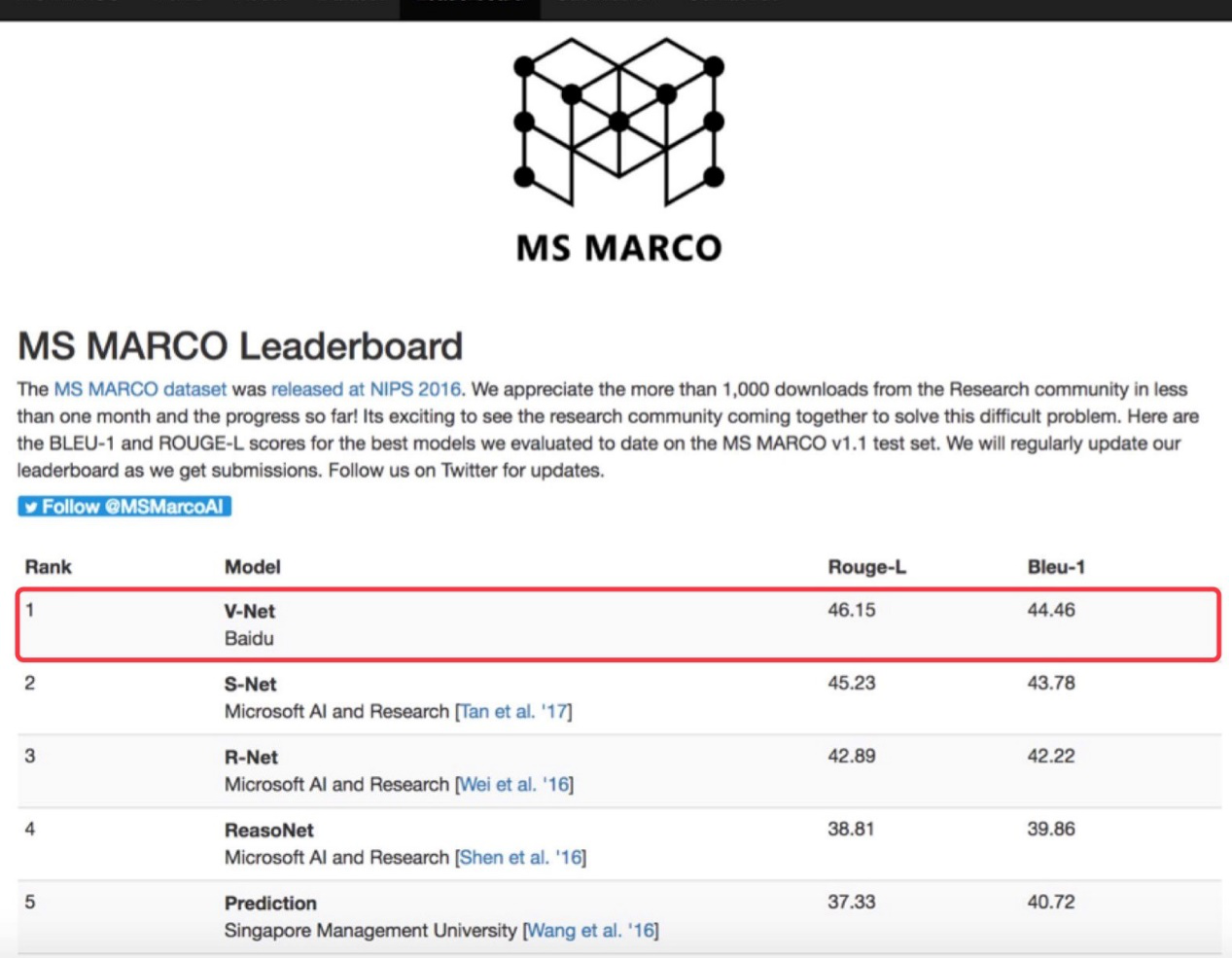
2月21日,百度自然语言处理团队研发的V-Net模型以46.15的Rouge-L得分登上微软的MS MARCO(Microsoft MAchine Reading COmprehension)机器阅读理解测试排行榜首。
加上此前斯坦福大学的SQuAD竞赛中,阿里、哈工大讯飞联合实验室等团队先后超越了人类平均水平。这意味着,机器阅读理解领域的两大***赛事:MS MARCO和SQuAD的记录先后由中国团队打破。
但在热闹的“军备竞赛”之余,机器阅读理解领域的深处并非一团和气。各种争议和辩论正在这场“机器答题大秀”背后上演。
比如说,为什么微软要紧随SQuAD之后另起炉灶,发布自己的数据集和竞赛?学术界关于机器阅读理解的争议为何一直不断?
这些疑问或许可以最终归因到一个问题:让AI做阅读理解,到底有什么用?
我们来聊聊“阅读理解圈”的江湖恩怨,以及接下来可预见的技术应用未来。
两大数据集对峙:机器阅读理解的问题与争议
所谓的机器阅读理解,基本概念跟咱们上学时做的阅读理解题很相似,同样都是给出一段材料和问题,让“考生”给出正确答案。所不同的,仅仅是机器阅读理解的主角变成了AI模型而已。
而机器阅读理解领域的比赛方式,就像斯坦福大学著名的AI竞赛ImageNet一样,都是由一个官方给定的数据集+一场跑分竞赛组成。各大科技巨头和世界名校的AI研究团队是主要参赛选手。
百度此次参与的机器阅读理解比赛,是微软在2016年末发布的MS MARCO。
这个赛事有趣的地方在于,其运用的训练数据是微软在产品实践中,从真实用户那里收集来的问题和答案。
这个数据集的问题全部来自于BING的搜索日志,然后又整理了这些问题获得的人工答案作为训练数据。这样做的优点在于,可以让AI模型通过最接近真实应用的语境来进行学习、训练和反向实践,完成“学以致用”的小目标。
圈内普遍认为,微软这么不容易地搜集一个源自真实网络的数据集,就是希望硬怼斯坦福大学的SQuAD。
2016年早些时候,斯坦福大学相关团队制作了一个用来测试AI模型阅读理解能力的数据集。与MS MARCO不同,SQuAD主要训练数据是来自维基百科的536篇文章,以及由人类阅读这些文章后,提出的10万多个问题及相关答案。
这种非常像校园考试的数据设定,从诞生之日起就争议不断。比如NLP领域的大牛Yoav Goldberg就认为这个数据集有些太过片面。SQuAD受到指责的地方,主要可以分为三个层面:
1、 问题过分简单。问题的答案主要源自于文档中的一个片段,真实应用场景中很少遇到这样的问题。
2、 数据多样性不足。SQuAD只有500多篇文章,内容不够丰富,训练出的模型被质疑难以处理其他数据或者更复杂的问题。
3、 通用性不强。为了跑分的方便,SQuAD的问题结构比较简单,涉及到的机器“推理”一面偏弱,导致其实用性数次受到怀疑。
举个简单的例子来描述一下两个数据集之间的不同:SQuAD大多数问题的答案来自文档本身,从文档中“复制粘贴”就能完成回答,这样模式固然更加方便,但客观上对问题类型和答案范围都做了限制,建立在SQuAD上的问题通常更加直白简单。而MS MARCO的问题则更倾向真实的语言环境,需要智能体推理语境进行分析。
萝卜白菜各有所爱,有人认为SQuAD是最方便测试的机器阅读理解比赛,也有人坚持MS MARCO是最接近人类问答习惯的竞赛。但争论的背后或许有一个共识正在浮现:机器阅读理解的应用性,已经开始受到产业的广泛关注。
进击的数据集:AI阅读也要重视“素质教育”
当然,MS MARCO的数据集结构同样也有很多争议。但相类似的“从生活中来”的机器阅读理解训练数据集正在越来越多。一句话总结这种趋势,大概就是大家发现,该让AI从“应试教育”变成“素质教育”了。
结构紧凑、体系清晰的SQuAD,虽然可以非常便捷地展现出AI模型的测试结果,但拓展性和实用性始终受到指责。许多学者认为,这个数据集有些被过分“考试化”了,导致其最终变成为了竞赛而竞赛。
而直接从互联网文本与产品实践问题中训练出的模型,被认为距离应用性更近。
其实仔细想想,机器阅读理解这项技术,从来都不是纸上谈兵的“象牙塔派”,在我们已经熟悉的互联网应用中,就有大量只能依靠机器阅读理解来解决的难题。
举个例子,当用户在搜索引擎寻找答案的时候,传统方案只能依靠用户互助来回答,正确性和效率都严重不足。但智能体进行回答,就不能只依靠关键词填空来处理。比如绝不会有用户提问“()是我国最长的河流?”;更多情况用户会询问复杂的问题,需要完整的解决方案和建议。那么,从真实提问数据中学习理解材料、回答问题的方案,近乎于AI技术满足搜索引擎体验升级的唯一出路。
再比如最近争议不断的内容推荐领域。今日头条最近反复出状况,很大程度来源于舆论指责其过度依赖关键词进行算法推荐,忽略了用户的对文章深度与知识性的需求。造成这种情况的原因之一,就在于算法的机器阅读理解能力不够,无法阅读真实的互联网材料,给出个性化的推荐结果。
除此之外,语音助手、智能客服等领域,都大量依靠于机器阅读理解阅读真实问题、真实互联网材料,给出完整答案的AI能力。从真实数据中训练AI,可能是破解这些难题的唯一途径。
中文、通识、应用:可预见的MRC未来
在我们猜想机器阅读理解的未来时,会看到几个比较明显的趋势。
首当其冲,目前机器阅读理解的训练数据集和竞赛,大部分集中在英文领域。这个尴尬正在一步步被打破。
比如百度在去年发布了与微软MS MARCO结构类似全中文数据集DuReader。其首批发布的数据集包含20万真实问题,100万互联网真实文档,以及42万人工撰写生成的答案。由此可见,在中国团队一次次挑战英文机器阅读理解记录的同时,直接作用于中文世界的机器阅读理解应该已经不远了。
另一方面,机器阅读理解的技术能力如何通用化、泛在化,与各种其他NLP技术体系相拟合,似乎成为了广为关注的话题。让机器能“理解”的同时,还能归纳、能思考、能创作,勾勒出完整的Deep NLP时代,也已经提上了日程。
再者,将机器阅读理解能力投入搜索、问答等应用领域,产生现实价值的应用案例正在增多。相信不久的未来,机器阅读理解工具化、集成化,可以渗透到各行各业当中,成为一种信息世界的主流解决方案。
比较大概率的状况,大概是不久的将来,我们会在信息流中感受到了种难以具体形容却又真实存在的体验提升。那就是因为机器正在“读你”,而不是“读题”。
【编辑推荐】
- 人工智能与机器学习或将成为公司CIO的制胜法宝
- 2018新零售五大趋势:无人零售风口继续蔓延,人工智能与物联网创造新价值
- 2018年IT***必须考虑的十大战略科技发展趋势
- 浩浩汤汤的“新零售”之战,2018会驶向何方
- 既要懂技术又懂产业,2018将是区块链正规军入场元年