【51CTO.com原创稿件】2017年12月01日-02日,由51CTO主办的WOTD全球软件开发技术峰会将在深圳中州万豪酒店隆重举行。本次峰会以软件开发为主题,数十位专家级嘉宾将带来多场精彩的技术内容分享。届时,平安人寿数据挖掘专家谢佳标将在编程语言与框架分会场与来宾分享"利用Microsoft R对大数据进行机器学习"主题演讲,为大家阐述Microsoft R在大数据机器学习中的优势,并利用快速逻辑回归、快速决策树、快速随机森林等算法对千万个用户记录进行欺诈预测,让听众能实际案例对Microsoft R有全面的认识。51CTO诚邀您莅临大会,与我们共享技术带来的喜悦。
51CTO记者对即将参加大会演讲的谢佳标老师进行了专访,让我们先睹为快,探听一下他是如何看待利用Microsoft R Server 对大数据进行机器学习。
为什么选择Microsoft R Server?

R语言***的优势是强大的软件包生态系统与图表优势,同时,CRAN上已有10000+个可以获取的R扩展包,内容涉及各行各业,可以适用于各种复杂的统计。
“R语言是数据从业者的利器,但其基于内存的诟病也一直被人所嫌弃。虽然这几年很多优秀的扩展包极大提升了R语言的性能,但在面对企业级大数据挖掘面前,也会显得力不从心。”谢佳标说。而企业版的Microsoft R Server 则凭借对“并行算法”的创新以及“模块化”的处理消除了内存的限制。
据悉, R语言于2015年被微软收购。目前,Microsoft R Server 可支持各种大数据统计分析,预测性模型和机器学习功能;支持基于R的全套数据分析过程-探索、分析、可视化和建模等。与R相比,Microsoft R Server的主要优势是:***、商业可行性方面,降低了开源软件的部署风险,因而减少企业使用开源产品的投入成本和风险;第二大数据处理方面,消除了内存限制,企业可实现对大数据集的处理;第三、处理线程由单线程处理变为并行线程,大大缩短分析时间。
Microsoft R Server在大数据进行机器学习的应用实例
机器学习探索可以预测数据的算法研究和建设,常被应用于大规模计算性任务。在本次采访时,谢佳标专家主要从以下几个数据挖掘流程来介绍Microsoft R Server如何进行机器学习:
***、数据导入
R是基于内存运算的,一般需要将待分析的数据集读入到R中才能对其进行数据处理、数据分析、数据建模及可视化等。但是,当遇到大数据集,R 就显得有点力不从心了。
而R Servere则可通过将数据集先保存为.xdf格式来避免上述这个问题。谢佳标以一份千万条记录的信用卡数据为例,向大家介绍如何利用rxImport函数实现将csv格式的大数据集保存为xdf文件。
如何实现?将函数的outFile参数设置为你要保存的文件名。具体代码:
> infile <- file.path(readpath,"ccFraud.csv")
> ccFraud_xdf <- rxImport(inData = infile,
+ outFile = "ccFraud.xdf",
+ overwrite = TRUE)
代码运行如截图所示:

rxGetInfo函数查看数据结构。当数据读取完毕后,可利用rxGetInfo函数查看.xdf文件的数据结构(将参数getVarInfo设置为TRUE),并查看数据的前十行(将参数numRows =设置为10)。
> rxGetInfo("ccFraud.xdf",getVarInfo = TRUE,numRows = 10)
代码运行结果如下图所示:

从上面结果可知,此份数据一共有一千万行九列,变量类型全部为整型,***给出前十行的数据。
第二步、数据预处理
在对数据进行分析或建模前,需对原始数据集进行处理,以达到模型要求。
gender字段现在为整型,其中数值1表示女性,2表示男性,在建模前需要对gender字段进行类型变换及重新编码。谢佳标以此份数据为例,利用stringsAsFactors,colClasse等实现数据转换。
如何操作?利用colInfo将变量gender从数值型变为因子型,且因子水平为“F”、“M”,利用colClasses将变量fraudRisk从数值型变成因子型。
> # 改变变量的数据存储类型
> ccFraud_xdf <- rxImport(inData = infile,
+ outFile = "ccFraud.xdf",
+ colClasses = c(fraudRisk = "factor"),
+ colInfo = list("gender" = list(type = "factor",
+ levels = c("1","2"),
+ newLevels = c("F","M"))),
+ overwrite = TRUE)
> # 查看ccFraud_xdf的数据结构
> rxGetInfo(ccFraud_xdf,getVarInfo = TRUE,numRows = 5)
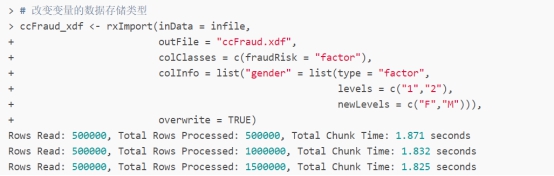

从上面截图可知,gender和fraudRisk变量的类型已经发生改变,从整型变成因子型,且gender的因子水平从1、2变成F、M。
第三、数据描述性统计分析
描述性统计是用来概括、表述事物整体状况以及事物间关联、类属关系的统计方法。
通过统计处理可以简洁地用几个统计值来表示一组数据地集中性和离散型。也可以通过rxSummary函数对.xdf文件进行描述性统计分析。
数值型变量,将返回变量的Mean(平均值) StdDev(标准差) Min(最小值) Max(***值) ValidObs(样本个数) MissingObs(缺失样本数);
离散型变量,将返回变量的因子水平个数、样本数、缺失样本数、各因子水平的样本数。
> # 利用rxSummary函数对数据进行描述性统计分析
> rxSummary(~.,ccFraud_xdf) # 对全部变量进行统计

从截图可知,creditLine变量的均值为9.13,标准差为9.64,最小值为1,***值为75,样本量为10,000,000,缺失样本量为0;gender变量的因子水平有两个,其中F的样本数为6,178,231,M的样本数为3,821,769。
第四、数据建模
在对数据进行处理和探索后,验证数据符合建模要求后,就可以将数据导入到模型中进行建模,并利用建立的模型对新数据进行预测。
利用rxLogit函数构建Logistic回归模型,在建立模型后用summary函数查看模型信息。具体代码如下:
> # logitic回归模型
> ccFraudglm <- rxLogit(fraudRisk ~ gender + cardholder + balance + numTrans
+ + numIntlTrans + creditLine,data = ccFraud_xdf)
> # 查看模型结果
> summary(ccFraudglm)
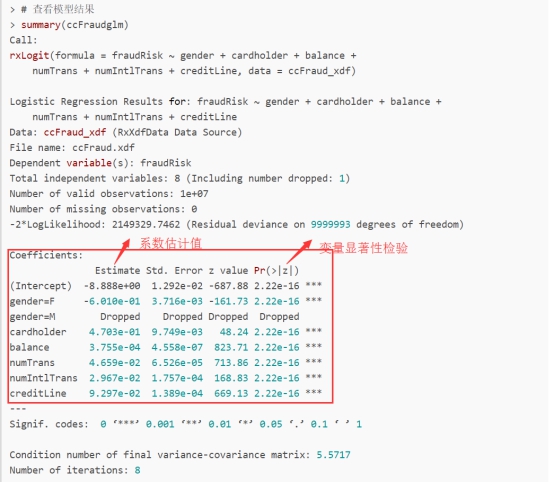
从截图可知,得到了逻辑回归模型的方程中的截距项和各因变量估计值,且有各变量显著性检验的P值。从结果来看,截距项和各变量都是极其显著的(***)。在得到合适的模型后,就可以利用rxPredict函数对新数据进行预测了。
写在***
微软的R Server其实是对开源R从研究角度向工业生产角度的一种努力,它解决了开源R在大数据量分析以及运维部署的一些不足。未来,它还会持续引进高级机器学习算法、新的模型以便于企业进行对大数据进行机器学习。
作者简介 :
平安人寿-数据挖掘专家谢佳标。目前供职于中国平安人寿数据挖掘专家一职,有十年以上数据挖掘工作实战经验,R语言资深用户,多次在中国R语言大会和大数据峰会作主题演讲。撰写书籍有《R语言与数据挖掘》、《数据实践之美》和《R语言游戏数据分析与挖掘》

使用优惠码[2017WOTDSZ],和我一起去WOTD全球软件开发技术峰会。8折优惠,仅剩48小时!详情点击wot.51cto.com
【51CTO原创稿件,合作站点转载请注明原文作者和出处为51CTO.com】