













假如,你手头上正有一个机器学习的项目。你通过各种渠道手机数据,建立你自己的模型,并且得到了一些初期的结果。你发现,在你的测试集上你只有80%的正确率,这远远地低于你的预期。现在怎么办,你怎么来改进你的模型?
你需要更多的数据吗?或者建立个更复杂的模型?还是说调整正则参数?加减特征?迭代更多次?不然全来一遍吧?
最近我的一个朋友也这么问我,他觉得改进模型就是全凭运气。这促使我决定写这篇文章,来告知应该怎么做一个有信息量,有意义的举措。
1. 偏差和方差
为了构建一个准确的模型,我们首先要了解模型带来的各种误差。
偏差:偏差误差是来源于模型的期望(平均)预测数值与真实数值之间的差值。
方差:对于一个给定的数值,模型预测结果的变异(波动)程度。
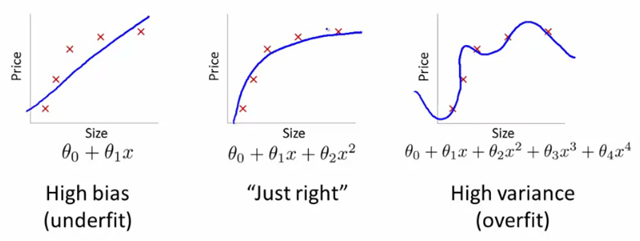
1.1 数学定义
我们想要预测Y,我们的输入是X。我们假设他们两个直接有关系,比如,其中误差项服从正态分布。
我们可能通过线性回归或者其他建模方法得到一个估计,然后在点处的期望误差的平方是:
这个误差能够被拆分成偏差和方差两个组成部分:
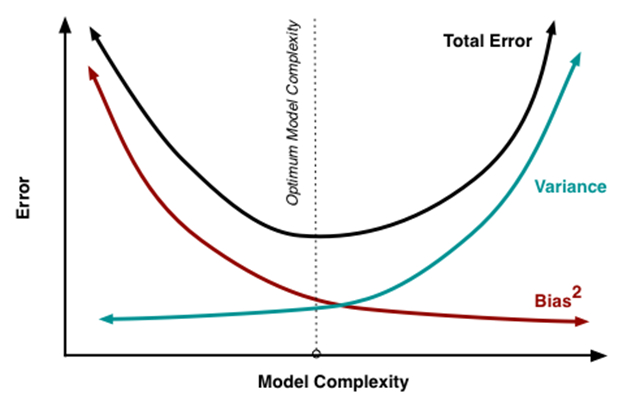
必不可少的误差来源于误差项,任何模型都不能够彻底地解决。只有给定问题本身的真实模型和无穷大的数据来修正它,我们能够让偏差和方差项都变成零。然而,在一个没有完美的模型和无穷的数据的世界里,我们必须要在减小偏差和方差中权衡。
2. 什么是学习曲线
现在我们知道权衡偏差和误差这件事了,但是如何改进我们的模型仍然有待考究。我们的模型面对 严重偏离 和 高度变异 的时候应该怎么处理?我们需要绘制模型的学习曲线来解答这个问题。
2.1 严重偏离
- 小训练样本:很小,并且很大。
- 大训练样本: 和都很大,并且两者近似相等。
2.2 高度变异
- 小训练样本:很小,并且很大。
- 大训练样本:随着训练集增加而变大,并且继续减小,但是不会稳定。,而且他们之间的差距很显著。
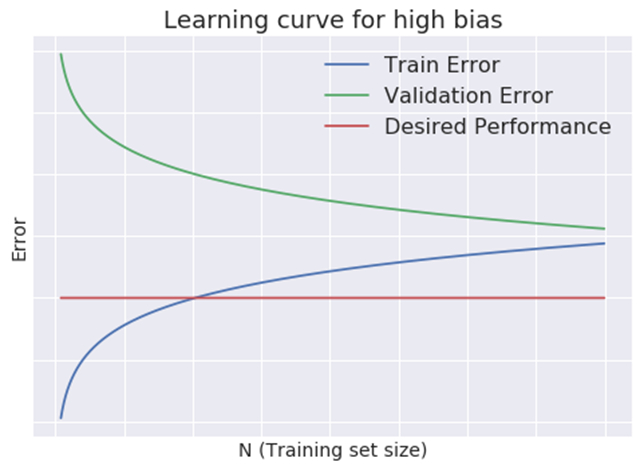
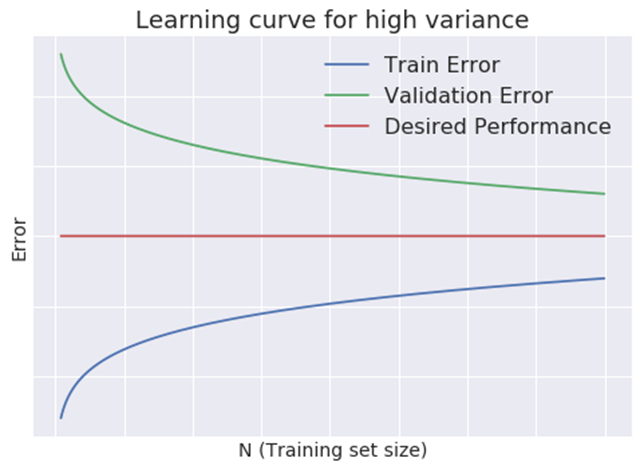
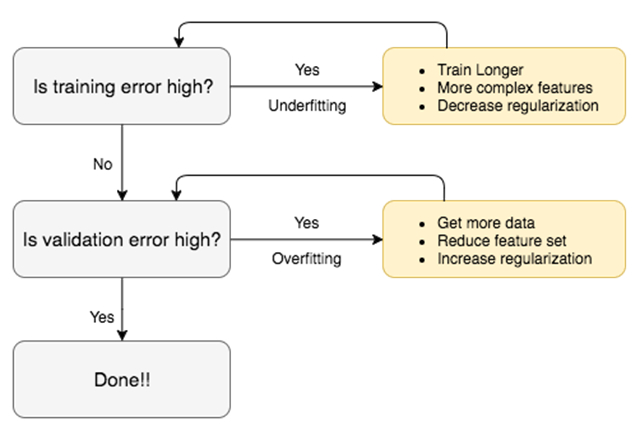
3. 下一步做什么?
我们已经明白,问题往往出在偏差或者方差上。这时候,我们要根据不同的情况,做出不同的抉择。
3.1 严重偏离
- 选择更复杂的特征,高阶项或者增加节点。
- 减小正则参数。
3.2 高度变异
- 收集更多的训练数据来帮助模型得到更好的泛化。
- 减小特征集合的大小。
- 增大正则参数。
4. 机器学习流程
大多数的机器学习系统都是由一个模型链组成的。通常情况下都会有一种困境,你已经有了一个机器学习的管道,但是接下来一步应该做什么呢?上限分析在这里很有帮助。
上限分析每一次在管道中的某一部分中插入一个完美的版本,并且由此来测度我们所观察到的完整的管道能够有多大的提升。这种方法能够帮助我们明白在整个模型链中,哪一步能够带来最可观的优化。

比如说上述的文字识别的管道(模型链),你发现一个完美的字符分割模型能够给整个识别系统提升1%,但是一个完美的字符识别模型能够提升7%。所以相比于改进字符分割模型,我们应该更关注字符识别模型的改进。
End.














